Un setup IA moins cher que Mario Kart World ?
🔴 Pourquoi faire de l’IA chez soi ?
C’est vrai ça, pourquoi faire de l’IA chez soi ? Et puis d’abord, c’est quoi l’IA ?
Qu’est-ce que l’IA ?
Selon Wikipedia :
L’intelligence artificielle (IA) est la capacité des machines à effectuer des tâches typiquement associées à l’intelligence humaine, comme l’apprentissage, le raisonnement, la résolution de problème, la perception ou la prise de décision. L’intelligence artificielle est également le champ de recherche visant à développer de telles machines ainsi que les systèmes informatiques qui en résultent.
En somme, l’IA, c’est utiliser des fonctions et des opérations mathématiques pour automatiser et accélérer des tâches complexes, en reproduisant des comportements humains comme la lecture, la vision, l’écriture ou encore la compréhension du langage. Grâce à ces calculs, les machines peuvent apprendre à reconnaître des images, comprendre du texte, prendre des décisions ou même créer du contenu, souvent plus vite et parfois mieux que nous (en vrai c’est discutable).
Mais pourquoi faire de l’IA chez soi ?
Déjà, j’aime avoir le contrôle total de ce que je fais et des outils que j’utilise. Pas par paranoïa, mais parce que j’aime comprendre les choses à ma façon — et pas selon celle d’un cloud provider, d’un SaaS ou de toute autre entité. Ça me permet d’apprendre ce qu’est l’IA, de comprendre la partie hardware et software, et de rencontrer des problèmes qu’on ne voit pas forcément ailleurs.
Mais il y a aussi plusieurs cas d’usage bien plus concrets :
- Souveraineté des données : garder le contrôle total de ses données sensibles.
- Économie financière : éviter les coûts élevés des services cloud, surtout sur le long terme.
- Personnalisation des modèles : entraîner ou affiner des modèles spécifiquement adaptés à ses besoins métier.
- Confidentialité et sécurité : réduire les risques de fuite ou vol de données.
- Disponibilité et latence : avoir un accès rapide à ses services d’IA, même sans internet.
🔧 Mon setup
Le hardware
Mon setup est basé sur un HP Z440 et contient :
- Alimentation HP 700W
- Intel Xeon E5-1620 v3 @ 3.50GHz
- 32 Go RAM DDR4 ECC 2133MHz
- SSD Samsung EVO 250 Go
- Quadro K2200 4 Go
- GTX 1050 Ti 4 Go
- GT 1030 2 Go
J’ai eu le Z440 avec CPU, alim et Quadro K2200 pour 45 €.
La RAM a été achetée sur Ebay pour 30 €.
Le reste, c’est de la récup !
Coût total : 75 €
Coût annoncé par Nintendo pour Mario Kart World : 79,99 €
P.S. Je m’étais dégoté une belle AMD Radeon Instinct Mi50 16 Go pour 129 € mais elle a décidé de rendre l’âme… Je n’ai malheureusement pas pu déterminer pourquoi.

Le software
Pour l’OS, mon choix s’est porté sur Ubuntu Server 24.04.
Pourquoi ? Parce qu’Ubuntu facilite énormément l’installation des drivers NVIDIA et bénéficie d’un meilleur support pour l’IA et le compute que d’autres distros comme Debian.
Côté apps et langages :
- Ollama : pour l’utilisation de LLMs
- NVtop : pour monitorer l’utilisation GPU façon htop
- Docker : pour containeriser mes apps et services
⚙️ Mise en place des prérequis
C’est la partie un peu reloue. Mettre en place tous les prérequis pour les applis citées ci-dessus prend du temps, de la doc, et pas mal de patience.
Installation des drivers NVIDIA & NVtop
D’abord, on liste les drivers disponibles :
sudo ubuntu-drivers devices
== /sys/devices/pci0000:00/0000:00:02.0/0000:02:00.0 ==
modalias : pci:v000010DEd000013BAsv0000103Csd00001097bc03sc00i00
vendor : NVIDIA Corporation
model : GM107GL [Quadro K2200]
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-550 - distro non-free
driver : nvidia-driver-570-server - distro non-free
driver : nvidia-driver-570 - distro non-free recommended # <=====
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-535 - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
P.S. On ne voit ici qu’une seule carte, c’est normal, c’est celle avec les dépendances les plus anciennes.
Ensuite:
sudo ubuntu-drivers autoinstall
Et voilà, avec Ubuntu, c’est presque trop simple.
Maintenant pour NVtop :
sudo apt install -y nvtop
On vérifie tout :
nvidia-smi # System Management Interface(Nous permet d'obtenir des infos plus détaillés sur nos cartes graphiques)
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.133.07 Driver Version: 570.133.07 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce GT 1030 Off | 00000000:01:00.0 Off | N/A |
| 0% 33C P8 N/A / 30W | 4MiB / 2048MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Quadro K2200 Off | 00000000:02:00.0 On | N/A |
| 42% 31C P8 1W / 39W | 10MiB / 4096MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA GeForce GTX 1050 Ti Off | 00000000:03:00.0 Off | N/A |
| 0% 25C P8 N/A / 120W | 5MiB / 4096MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
OK ! Toutes nos cartes sont là, maintenant on test NVtop
nvtop
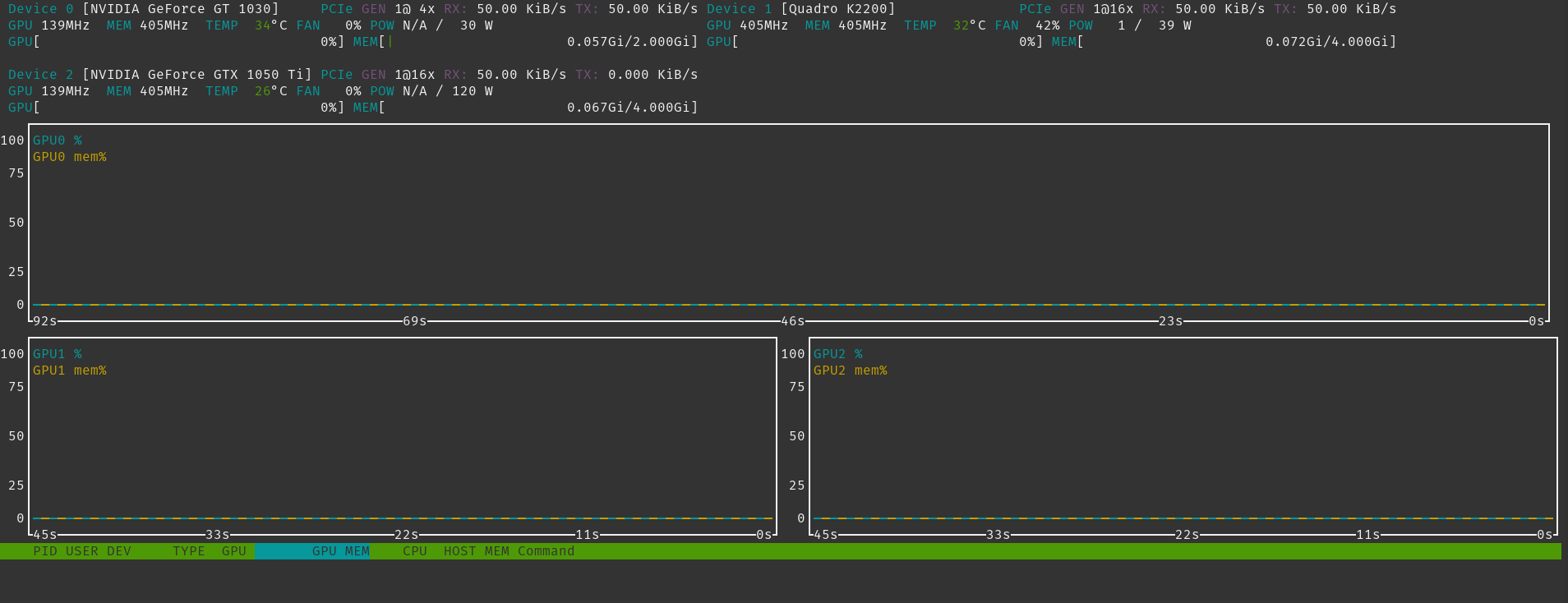
Magnifique !
Installation de Docker & Nvidia Container Toolkit
Nvidia Container Toolkit ? C’est quoi encore cette m*rde ?
C’est ce qui vas nous permettre d’utiliser nos cartes graphiques(GPU) dans des containers Docker.
Avant de passer à cette étape il faut installer Docker :
curl https://get.docker.com | sh
P.S. Cette méthode d’installation est rapide, mais à éviter en prod ! En cas de compromission de
get.docker.com, un malware ou autre peut vite prendre le controle de votre machine.
Et maintenant, Nvidia Container Toolkit :
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Cette commande ajoute les repositories officiel pour le Nvidia Container Toolkit et les clées GPG nécéssaire.
On met à jour nos sources :
sudo apt update
On installe les paquets nécéssaires :
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1 # Bien penser à mettre la dernière version pour avoir toutes les MÀJ et patches !
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
Maintenant, place à la partie technique :
sudo nvidia-ctk runtime configure --runtime=docker
Cette commande va mettre à jour le fichier /etc/docker/daemon.json pour dire à Docker d’utiliser le runtime Nvidia Container Toolkit afin de pouvoir communiquer avec les GPU de façon plus sécurisée, plus stable et plus normée que de monter le ou les GPU en tant que device dans des containers.
Et ensuite, on redémarre Docker pour que les changements prennent effet :
sudo systemctl restart docker
Petit test :
sudo docker run --rm --gpus all nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.133.07 Driver Version: 570.133.07 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce GT 1030 Off | 00000000:01:00.0 Off | N/A |
| 0% 36C P8 N/A / 30W | 4MiB / 2048MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Quadro K2200 Off | 00000000:02:00.0 On | N/A |
| 42% 32C P8 1W / 39W | 10MiB / 4096MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA GeForce GTX 1050 Ti Off | 00000000:03:00.0 Off | N/A |
| 0% 27C P8 N/A / 120W | 5MiB / 4096MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Et BAM ! Tous nos GPU sont vus et utilisables par nos containers !
P.S. c’est graçe à l’option
--gpus allque tous les GPU sont vus par le container.
🖱️ Maintenant on s’amuse :
Tous les pré-requis sont installés, on peut enfin s’amuser !
Ollama et modèle de langage :
Pour commencer, on va utiliser Ollama un super outil qui nous permet d’installer et d’utiliser des modèle de langage comme :
Ici, pas de container(même si c’est possible), on ne s’embête pas :
curl -fsSL https://ollama.com/install.sh | sh
Et on est paré :
ollama run gemma3:1b
On choisi un petit prompt comme You are a history teacher and you are going to teach me something about the city of New York.
Et on regarde l’usage de nos GPU via NVtop :
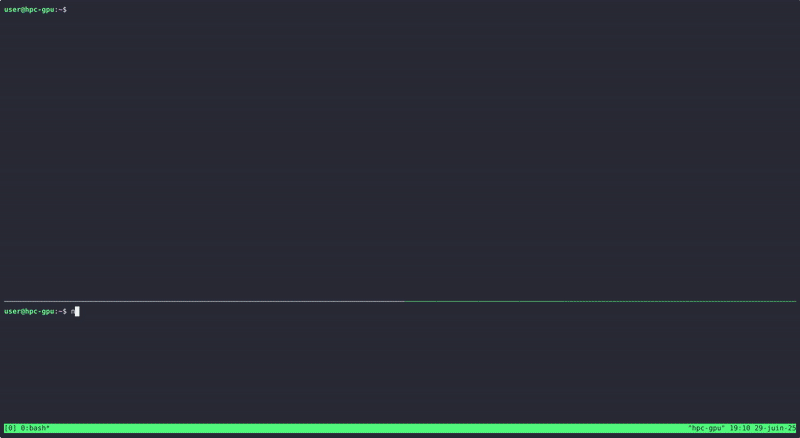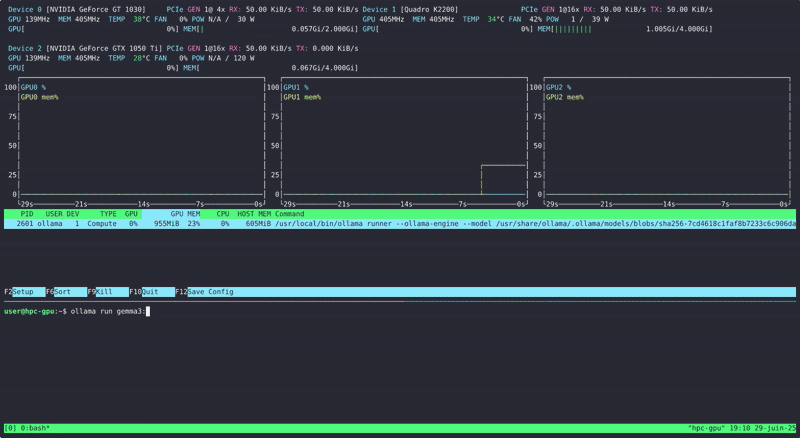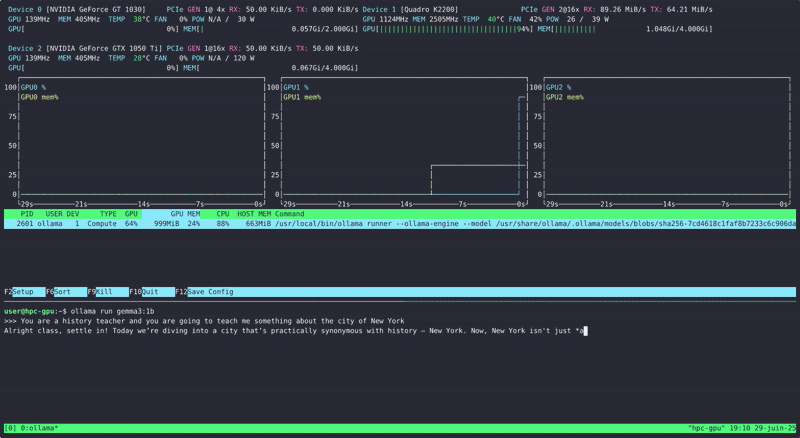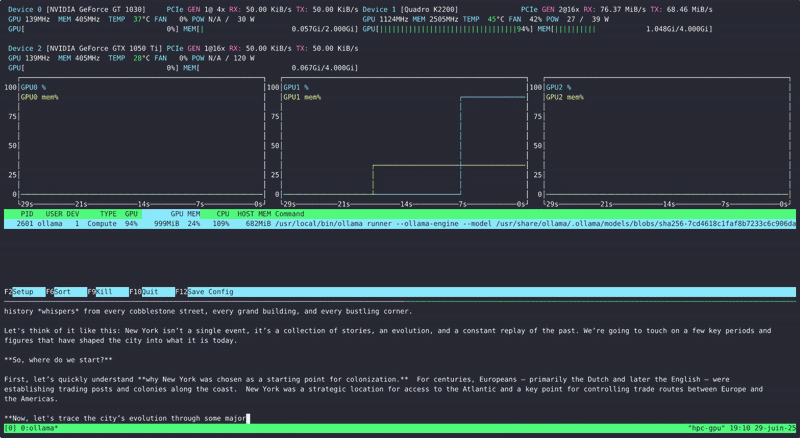
Parfait ! On arrive à lancer des modèles de langage sur nos GPU (ici seulement 1 due à la taille du modèle qui est d’environ 800Mo)
Tensorflow et entrainement :
Utiliser des modèles c’est bien, mais en coder soit même, c’est encore mieux !
Là, ça va être très technique, je vous préviens. On va parler de :
- Tensorflow : librairie Python pour l’IA et l’apprentissage automatique.
- Dataset : jeu de données sur lequel on se base pour entrainer notre model.
- Jupyter Notebook : environnement Web interactif pour développer et visualiser notre modèle.
- Deep Convolutional Generative Adversarial Network(DCGAN) : faire se battre 2 modèles de machine learning utilisant des convolution, un pour créer des images, l’autre pour influencer le premier à faire des images plus réalistes.
Bon en réalité, ici, je ne vais rien coder. Je vais utiliser le code proposé par Tensorflow pour voir s’il est possible d’entrainer un modèle sur mon serveur.
P.S. L’entrainement et l’inférence d’un modèle d’IA n’ont rien à voir au niveau de l’utilisation des ressources. En général, entrainer un modèle consomme plus de ressources que d’inférer sur un modèle.
D’abord, un peu de magie. Au lieu d’appliquer des configurations réseaux compliquées, on va ouvrir un tunnel SSH :
ssh -L 8888:0.0.0.0:8888 user@gpu-server
Pourquoi ? Parce que par défaut, un serveur Jupyter n’écoute qu’en localhost(127.0.0.1).
Ensuite, lançons notre container Docker :
sudo docker run --gpus all -it --rm -p 8888:8888 quay.io/jupyter/tensorflow-notebook:cuda-ubuntu-24.04
Et c’est partie pour le fun !
On se connecte à notre notebook via l’URL donnée par Jupyter et tadaa !
Et on importe le notebook DCGAN de chez Tensorflow à la racine du dossier.
Maintenant on lance et on attend.
Que fait le notebook ?
Pour simplifier, le notebook va, dans l’ordre :
- Importer les libs nécessaires
- Charger le Dataset MNIST (60k image de chiffre de 0 à 9 écrits à la main)
- Créer le modèle
générateurqui s’occupe de créer des images de nombres en partant de bruit (une image greyscale avec des pixels aléatoires) - Créer le modèle
discriminantqui lui vas dire augénérateursi l’image est vrai ou fausse en se basant sur le Dataset pour qu’il puisse générer d’autres images plus réalistes - Définir la boucle d’entrainement, qui vas générer 16 images sur 50 itérations (EPOCHS), et sauvegarder un
checkpoint(un état des poids du modèle général dans le temps) toutes les 15 itérations. - Et nous créer un magnifique GIF à la fin pour nous montrer l’évolution de la génération des images pour chaque itération.
Après 30.501 secondes voici notre 1ère génération :

C’est flou, on comprend rien, c’est normal ! c’est la première génération, l’entrainement ne fait que commencer.
En attendant la fin de l’entrainement, regardons ce qu’il se passe côté utilisation de ressources :
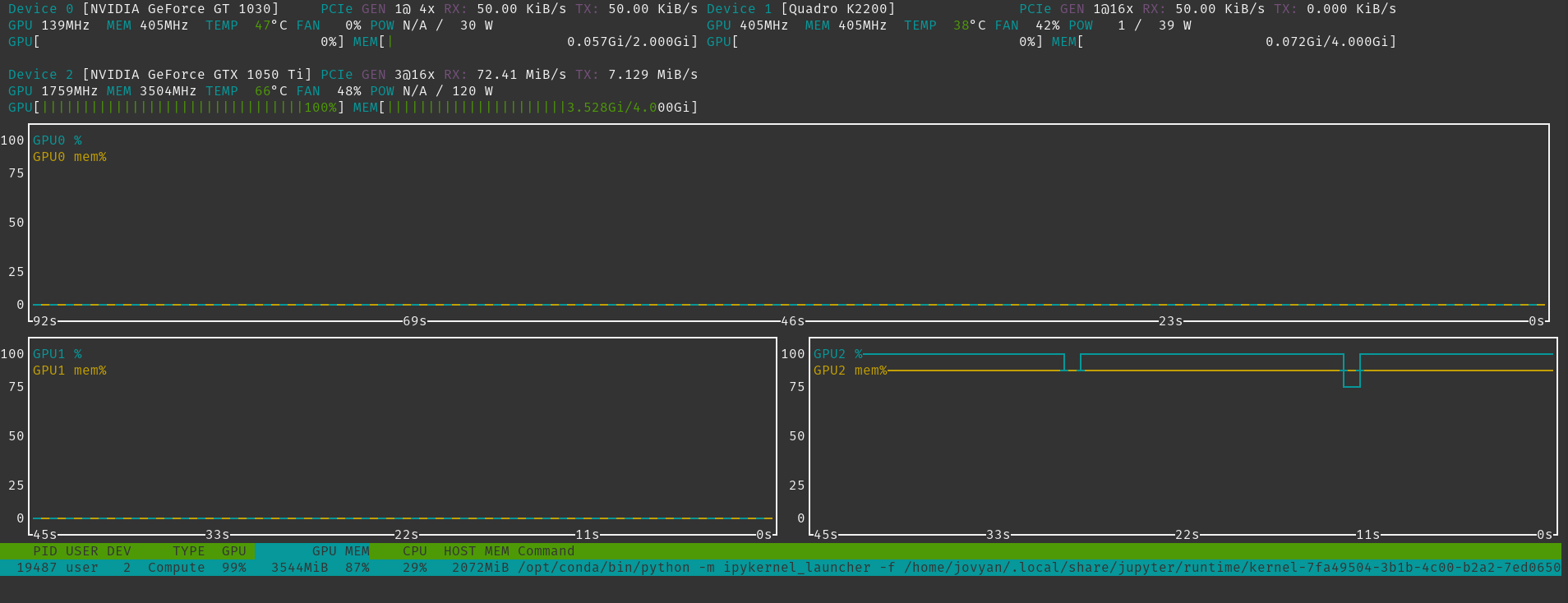
WOW ! VRAM pleine à craqué, utilisation du GPU à quasi 100% Mais pourquoi 1 seul GPU ? J’en ai 3 !
C’est très simple. Entrainer un modèle sur plusieurs GPU, c’est possible, mais pas sans configuration supplémentaire.
Le notebook utilisé n’est pas codé pour run sur plusieurs GPU. Mais cela viendra dans un prochain article, je vous rassure.
Ah !, c’est cuit ! Le modèle a fini son entrainement.
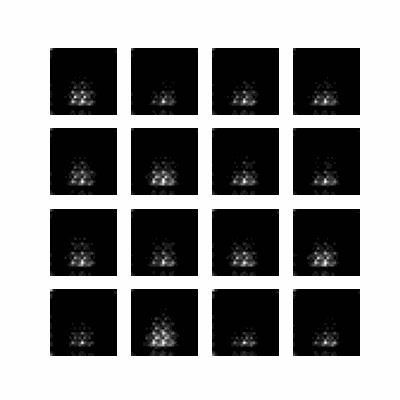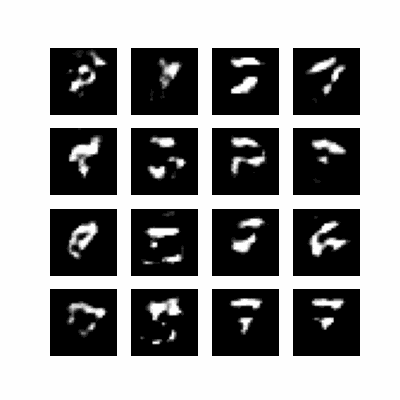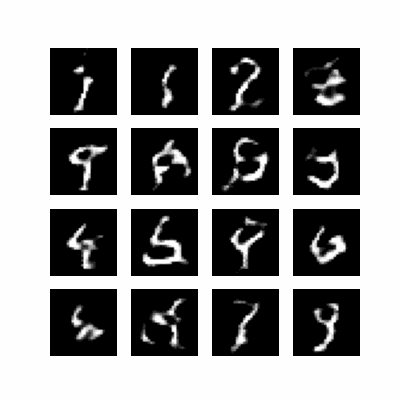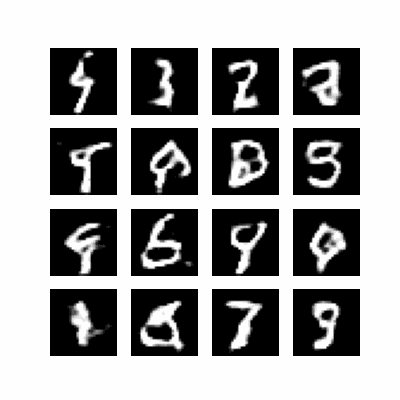
Bon… c’est moche, mais ça a marché ! On distingue assez clairement des chiffres :
4 | 3 | 2 | ?
9 | 8 | ? | 9
? | 6 | 9 | ?
? | ? | 7 | 9
Sur 16 chiffres, seuls 4 ne sont vraiment pas lisibles, mais on a prouvé qu’on peut entrainer un modèle !
🔚 Conclusion
Après tout ce chemin, qu’est-ce qu’on a appris ?
Pour moins de 80€, on a pu faire installer plusieurs outils liés à l’IA, on a entrainé un modèle d’IA génératrice d’image, on a utilisé un LLM pour lui poser des questions, mais est-ce que ça en valait la peine ?
Bah à mon sens… Carrément !
Alors, OK, au niveau de la consommation de courant, on va vite finir dans le rouge et les GPU utilisés ne sont vraiment pas optimales pour devenir le prochain OpenAI.
Mais j’ai appris énormément de choses :
- Mettre en place un environnement de développement containérisé pour entrainer un modèle de génération d’image
- Mis les pieds dans le monitoring d’utilisation GPU
- Utiliser un LLM en local
- Même si on ne l’a pas vu ici, mais que ce n’est pas parce que j’ai 3 GPU que je peux magiquement faire plus de choses
Et tout ça pour moins cher que Mario Kart World !
P.S. Il se peut que je fasse un second article avec des précisions, d’autres tests, et peut-être même du cloud-gaming