Mon premier projet avec un NPU (Hailo‑8L) : de MNIST à l’inférence embarquée
🎯 Pourquoi ce projet ?
Au départ, je pensais que le Hailo‑8L c’était un genre de puce magique : Où tu peux run des LLM, l’utilisé en tant que device sur des framework comme Tensorflow, faire de l’entrainement de model,
Spoiler : Absolument pas
En creusant un peu, j’ai compris que le Hailo‑8L est fait uniquement pour faire de l’inférence, pas d’entraînement, et encore moins du [Reinforcement Learning] ou autre LLM en tout genre.
C’est une puce ultra-efficace, mais spécialisée, conçue pour faire tourner des modèles déjà entraînés sur des systèmes embarqués (caméras, robots, edge devices…).
Alors j’ai testé les modèles pré-existants de Hailo — et c’était quasiment que des modèles de vision par ordinateur : classification d’images, détection d’objets, segmentation, etc.
Sauf qu’honnetement, moi j’me fous un peu de ça. Ce que je voulais, c’était coder mon propre modèle IA, comprendre ce qu’il y a sous le capot, et le faire tourner sur mon hardware.
Du coup, j’ai décidé de partir from scratch, avec MNIST, le dataset “Hello World” du deep learning. Mon objectif :
- Créer mon tout premier modèle de A à Z
- Le faire tourner en local sur le Hailo‑8L
- Comprendre toute la chaîne de bout en bout
Si tu veux jeter un œil au code complet, tout est dispo 👉 ici.
🔧 Mon setup (hardware + software)
🧱 Côté matos
J’utilise un Raspberry Pi 5, tout simplement parce que c’est le seul Pi qui est compatible avec le NPU Hailo‑8L.
Pourquoi ? Parce que le Hailo‑8L se connecte en PCIe, et c’est le seul Pi qui expose une vraie ligne PCIe accessible facilement.
Le NPU est branché via une carte nape PCIe x1. Tout est expliqué dans la doc Raspberry Pi, que j’ai suivie pour l’install des paquets côté Raspberry.

💻 Côté software
Sur le Pi :
- Installation des paquets Hailo (SDK + runtime) pour pouvoir faire tourner les modèles
- Utilisation de HailoRT pour charger le modèle sur le NPU et lancer l’inférence
Mais pour la compilation du modèle, c’est un peu plus chaud :
Le Hailo Dataflow Compiler (DFC), qui permet de convertir un modèle TensorFlow ou ONNX vers un exécutable .hef pour le NPU, ne tourne que sur x86_64 et est disponible en source fermé sur Hailo Developper Zone.
Du coup j’ai tout mis en place sur mon PC perso (sous Pop OS), et c’est là que j’ai entraîné, exporté et quantifié mon modèle.
🤔 Petite découverte au passage
Au début je comprenais rien à leurs specs : ils parlaient de “26 TOPS”, mais pas de TFLOPS, et je comprenais pas trop le délire.
En fait c’est parce que le Hailo‑8L ne fait pas de float du tout. Il bosse exclusivement en INT8 (entiers 8 bits), ce qui explique pourquoi il est aussi rapide et aussi économe.
Donc si tu veux que ton modèle tourne dessus, faut quantifier ton modèle float16 → int8 via le DFC, sinon c’est mort.
⚙️ Les grandes étapes du projet
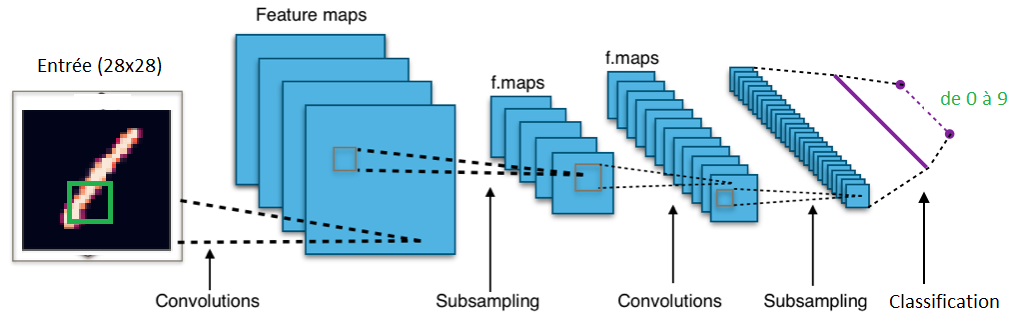
1️⃣ Entraînement du modèle MNIST
J’ai commencé par créer un modèle simple, stable et fonctionnel, en l’entraînant sur le dataset classique MNIST (les chiffres manuscrits).
Pour ça, j’ai utilisé Keras, parce que c’est simple et efficace pour prototyper vite.
2️⃣ Exporter le modèle
Une fois entraîné, il a fallu voir dans quel format je pouvais exporter ce modèle pour pouvoir le convertir ensuite avec les outils Hailo.
J’ai exploré plusieurs formats :
.keras(le format natif Keras).tflite(TensorFlow Lite, souvent utilisé pour l’embarqué).onnx(Open Neural Network Exchange), qui est le plus commun et supporté par la plupart des frameworks et outils, donc c’est celui que j’ai privilégié.
3️⃣ Découverte et prise en main du Hailo DFC
Ensuite, je me suis familiarisé avec le Dataflow Compiler (DFC) de Hailo.
Cet outil prend le fichier .onnx ou .tflite et le compile en un format propriétaire .hef optimisé pour le NPU Hailo.
En plus, il permet de faire la quantification en INT8 obligatoire pour ce hardware.
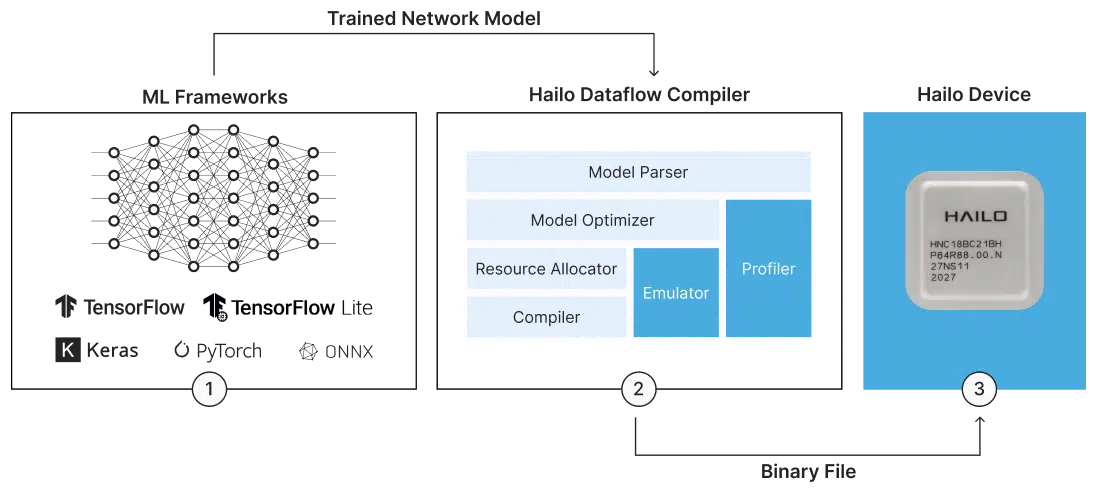
4️⃣ Compilation et déploiement sur le Raspberry Pi
Avec mon fichier .hef en poche, j’ai transféré tout ça sur mon Raspberry Pi 5 équipé du NPU.
Grâce au runtime HailoRT, j’ai pu lancer l’inférence directement sur la puce, et valider que tout tournait bien.
Ça fait un peu geek, mais voir ton modèle tourner sur une puce embarquée, c’est un vrai kif ! 😎
💡 Ce que j’ai appris / À retenir
Un truc hyper important à comprendre avec les NPU (que ce soit le Hailo‑8L, le Google Edge TPU Coral, ou d’autres), c’est qu’ils ne font pas d’entraînement.
Ce sont des puces uniquement dédiées à l’inférence — c’est-à-dire qu’elles exécutent des modèles déjà entraînés, en mode super optimisé et basse consommation.
Du coup, il faut toujours :
- D’abord entraîner ton modèle sur un PC ou serveur classique quitte à avoir des GPU
- Ensuite compiler ce modèle avec un outil spécialisé (comme le Dataflow Compiler chez Hailo) pour générer un fichier exécutable compatible avec la puce
- Puis déployer ce fichier compilé sur la puce pour faire l’inférence en temps réel
Si tu t’attends à faire de l’entraînement directement sur un NPU, tu vas perdre du temps. Ces puces sont faites pour déployer du ML à la vitesse de l’éclair, pas pour apprendre de nouvelles données.
📎 Liens utiles
- Le repo complet (code + tuto détaillé) : github.com/l-nmch/hailo-mnist
- SDK Hailo : hailo.ai
- Forum Hailo (très utile !) : community.hailo.ai
🧠 Terminologie
| Terme | Définition rapide |
|---|---|
| NPU (Neural Processing Unit) | Processeur spécialisé pour exécuter rapidement des modèles d’IA, en particulier des réseaux de neurones. Optimisé pour l’inférence. |
| Inférence | Étape où le modèle, déjà entraîné, est utilisé pour faire des prédictions (par ex. reconnaître un chiffre). |
| Entraînement | Phase où le modèle apprend à partir de données. Nécessite généralement beaucoup de ressources (GPU/TPU). |
| INT8 | Format numérique entier codé sur 8 bits. Moins précis que float32, mais plus rapide et léger pour les NPU. |
| Quantification | Processus de conversion d’un modèle entraîné en float32/float16 vers INT8 pour qu’il soit exécutable sur du hardware spécialisé. |
| TOPS (Tera-Operations Per Second) | Unité de mesure des performances pour les puces IA. Différent de TFLOPS car souvent utilisé avec des opérations INT8. |
| ONNX (Open Neural Network Exchange) | Format de modèle IA open-source, compatible avec plusieurs frameworks (TensorFlow, PyTorch, etc). |
| .hef | Format compilé propriétaire utilisé par Hailo pour ses NPU. Généré par le Dataflow Compiler. |
| HailoRT | Runtime fourni par Hailo pour charger un .hef sur le NPU et exécuter les inférences. |
| Dataflow Compiler (DFC) | Outil de Hailo (PC x86_64 only) pour compiler et quantifier les modèles vers le format .hef. |
✅ Conclusion
J’espère que cette mini-aventure t’a donné envie de tester du edge AI toi aussi.
Si t’as un Hailo‑8L ou autre NPU sous la main, franchement, fonce.
Et si tu veux reprendre mon code pour tester, go : c’est open-source 💡